内容纲要
存储高可用
本质
本质是将数据复制到多个存储设备。
存储高可用的复杂度
复杂度提现在应对复制过程中的延迟和中断导致的数据不一致问题。
常见高可用架构
- 主备
- 主从
- 主主
- 集群
- 分区
常见双机高可用架构
双机架构假设主机能够存储所有数据。
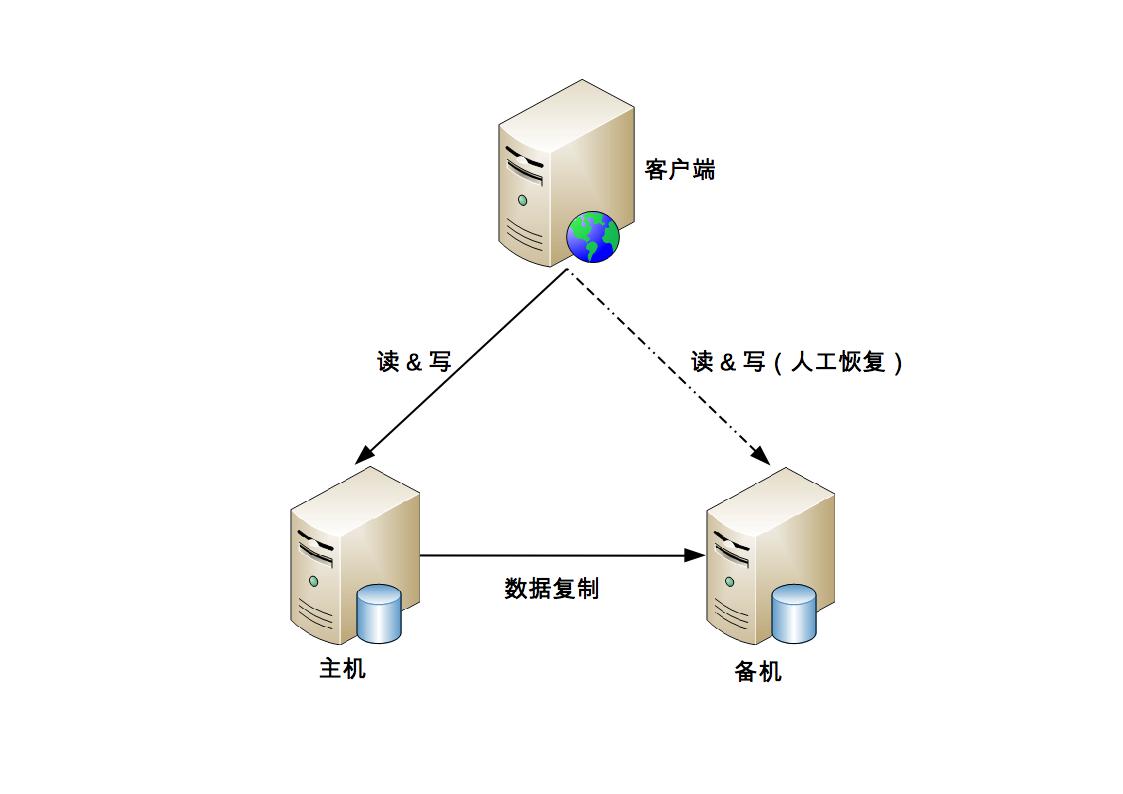
主备
原理
主机提供服务;备机提供备份(备机改主机需要人工干预)
优点
- 简单
- 客户端不需要知道备机的存在
- 主备机只需进行数据复制
缺点
- 硬件资源浪费
- 备机只有数据备份功能,不提供读写能力
- 切换需要人工干预
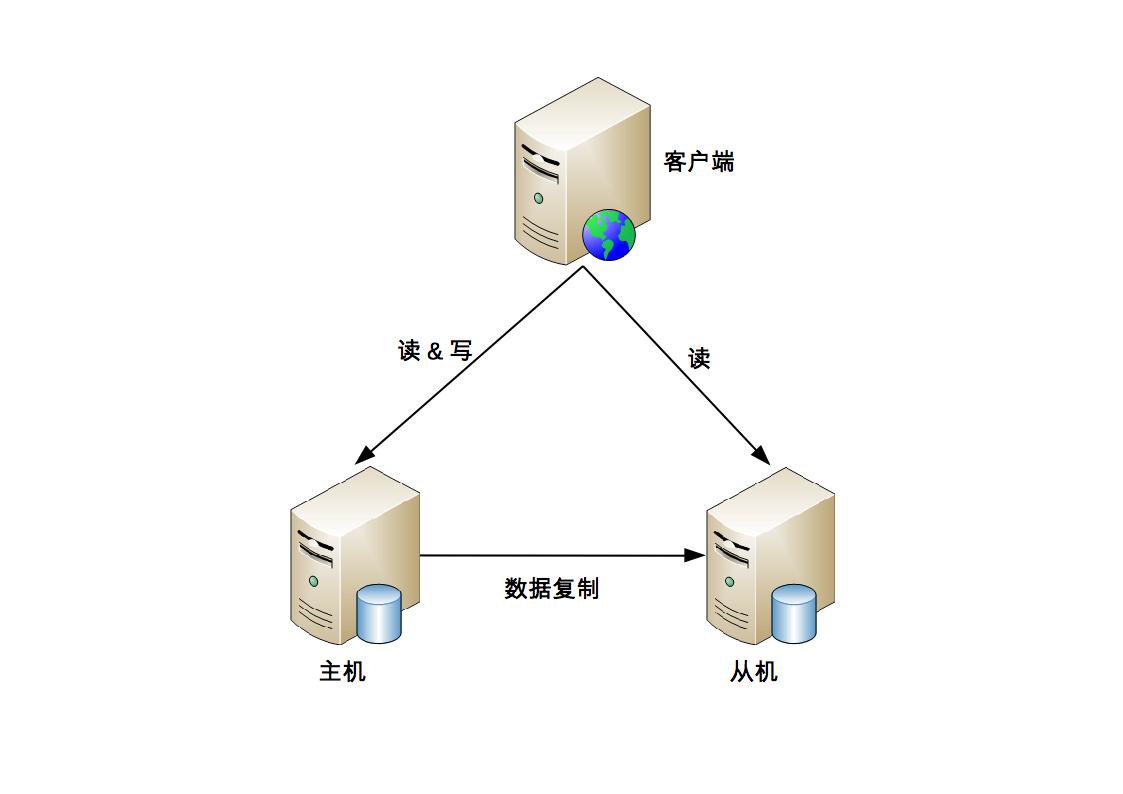
主从
原理
主机提供服务;备机备份数据且提供读服务
优点
- 高可读
- 主机出现故障时,从机可读
- 硬件资源利用率略高
- 从机提供读服务
缺点
- 复杂度增加
- 客户端需要知道主从机存在(将不同的操作发给不同的机器)
- 数据不一致风险
- 如果主从复制延迟较大,存在数据不一致风险
- 故障需要人工干预
主备/主从切换(双机切换)
原理
切换
主备切换
- 状态判断
- 状态传递的渠道
- 状态检测的内容
- 切换决策
- 切换时机
- 切换策略
- 自动程度
- 数据冲突解决
- 常见架构
- 互连式
- 中介式
- 模拟式
互连式
主备机直接建立状态传递渠道。
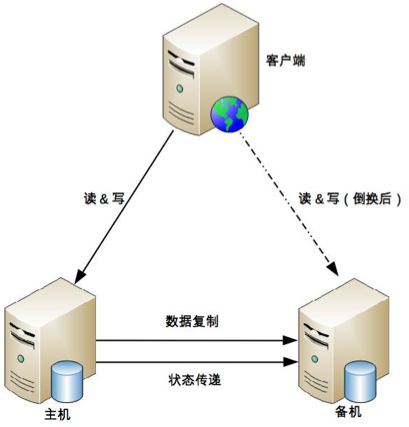
优点:
- 不依赖第三方
缺点:
- 连接管理复杂
- 传递通道异常
- 双主(备机检测通道异常,判断主机异常(主机实际正常),自动升级为主机)
- 传递通道异常
中介式
通过第三方中介传递状态。
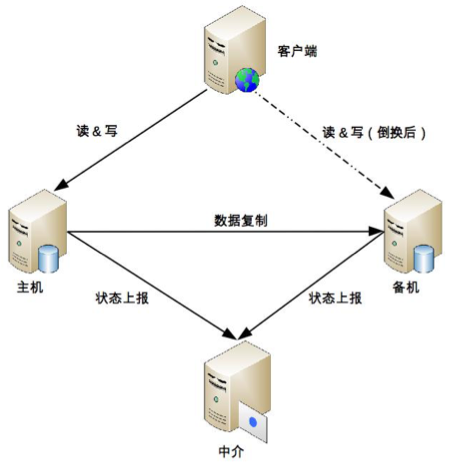
优点:
- 连接管理简单
- 状态决策简单
- 主备机初始都是备机
- 只要与中介断开,自动降级为备机(重连上以备机状态上报中介)
- 主机断开后,中介立即通知备机(备机自己升级为主机)
- 主备机连接都正常情况下,根据实际情况决定主备机是否切换
缺点:
- 中介可靠性问题(高可用地狱)
- 目前推荐 Zookeeper 搭建中介切换架构
模拟式
主备不传递状态,备机模拟客户端行为来判断主机状态。
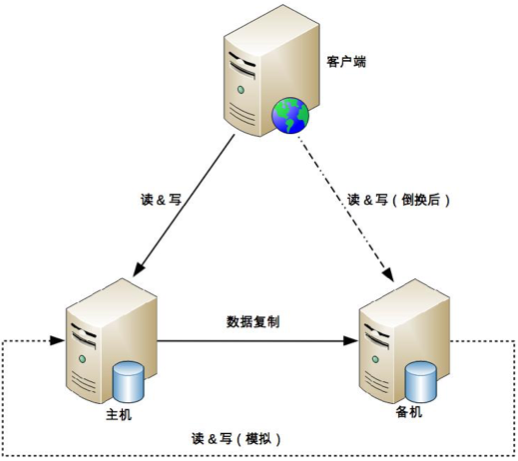
优点:
- 实现简单(省去状态通道管理)
缺点:
- 简单
- 状态有限:只有响应信息
- 决策偏差:状态有限(缺少负载情况、响应时间等),决策出现偏差
主从切换
略
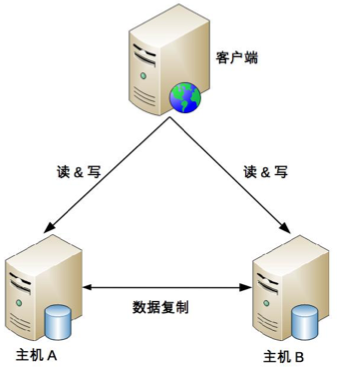
主主
原理
两台都是主机,互相将数据复制给对方。
优点
- 不存在切换概念
- 客户端无需区分角色(都是主机)
缺点
- 部分数据不能双向复制(用户 ID、库存等)
集群
双机架构假设主机能够存储所有数据。然而主机本身的存储、处理能力肯定是有极限的。
集群简单来说就是多台(3 台及以上)机器组合在一起形成一个统一的系统。按角色划分,可以分为:
- 数据集中集群
- 数据分散集群
数据集中集群
数据集中集群架构上类似主备、主从等,通常是 1 主多备,1 主多从(写操作只有主机支持,读操作参考主备、主从架构)。
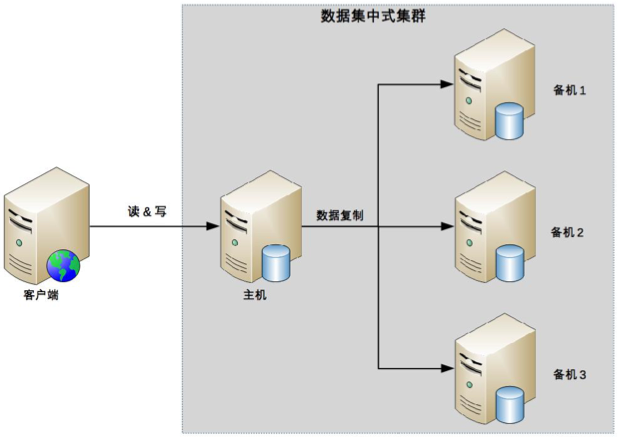
数据集中集群的复杂度
- 主备机数据复制
- 多通道复制
- 给主机带来读写压力
- 需要思考如何降低压力
- 备机数据不一致风险增加
- 需要对备机数据做一致性检查和修正(某些场景可能不需要)
- 给主机带来读写压力
- 多通道复制
- 备机检测主机状态
- 多备机情况下,不同备机得出的主机状态可能不一致
- 主机故障,备机选主
- 多备机,每台备机都有成为主机的资格
- 通过算法进行选举等(算法复杂度高)
- 多备机,每台备机都有成为主机的资格
应用场景
数据集中集群适合数据量不大(单台服务器能够支撑),集群机器不多的场景。
数据分散集群
数据分散集群指由多台服务器组成集群,每台服务器负责存储部分数据,同时备份部分数据。
数据分散集群的复杂度
- 如何将数据分配到不同的服务器上
- 均衡性
- 算法需要保证数据基本均衡分布在不同的服务器上
- 容错性
- 算法需要将出现故障的服务器上的数据分区分配给其他服务器
- 可伸缩性
- 算法需要在集群因容量不够进行扩容后,自动把部分数据分配到不同的服务器上,并保证服务器均衡
- 均衡性
应用场景
数据分散集群适合数据量超大,集群机器需要可以无限伸缩的场景。
分区
数据集群解决的是集群单点故障的场景。对于大型灾难(汶川大地震、印度洋海啸等),需要地理级别的解决方案。
数据分区是指数据按照一定的规则进行分区,不同分区分布在不同的地理位置上,每个分区存储一部分数据。当灾难发生时,只损失部分数据(部分数据当时不可用),在故障恢复后,其它地区的备份数据可以帮助故障地区恢复数据。
分区的复杂度
- 数据量
- 数据量大直接导致分区规则、复制规则复杂度和资源消耗上升
- 分区规则
- 分区规则多样,具体采用哪种需要考虑业务范围、成本等因素
- 洲际分区:面向不同大洲;地理跨度大,网络延迟高
- 不适合提供在线服务
- 数据中心可以不互通,只提供备份服务
- 国家分区:面向不同国家;国家语言、文化、法律不同
- 一般也只提供备份服务
- 城市分区:在同一个国家或地区内;网络延迟低。业务相似
- 分区同时提供对外服务(提供异地多活等需求)
- 洲际分区:面向不同大洲;地理跨度大,网络延迟高
- 分区规则多样,具体采用哪种需要考虑业务范围、成本等因素
- 复制规则
复制规则详解
集中式
集中式备份存在一个总的备份中心,所有分区数据都备份到备份中心。
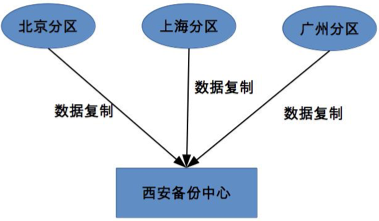
优点:
- 设计简单:分区间互不影响
- 扩展容易:随意增加分区,只需将新增分区数据备份到备份中心
缺点:
- 成本高:需要一个完整的数据中心
- 备份中心容灾弱:备份中心故障影响全部分区备份
互备式
互备式备份指每个分区同时备份另一个分区的数据。
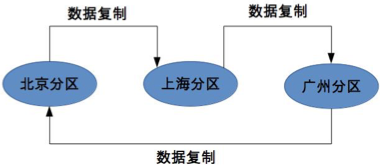
优点:
- 成本稍低:利用现有设备处理能力,增加部分存储空间(存储相对便宜)
缺点:
- 设计复杂:分区互相影响(各个分区除了要提供服务,还要备份其它分区数据)
- 扩展麻烦:新增分区需要重新调整备份指向
独立式
独立式备份指每个分区有自己的备份中心(服务区和备份中心异地)。
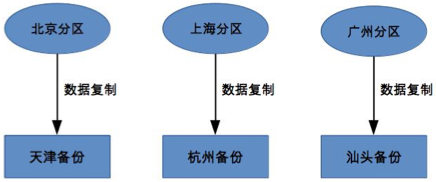
优点:
- 设计简单:分区互不影响
- 扩展容易:新增加的分区只需要搭建自己的备份中心即可
- 容灾强:备份中心故障影响范围小(只影响某分区)
缺点:
- 成本高:每个分区除了硬件资源,还有场地等额外成本