内容纲要
服务追踪的作用
- 快速定位请求事变原因
- 优化系统瓶颈(快速定位系统瓶颈出现的地方)
- 优化链路调用(分析依赖关系,可能减少依赖)
- 生成网络拓扑(标明服务间的依赖关系,方便全局观察)
- 透明传输数据(统一传递某些数据给多个服务,用来做 A/B 测试等)
服务追踪系统
核心理念
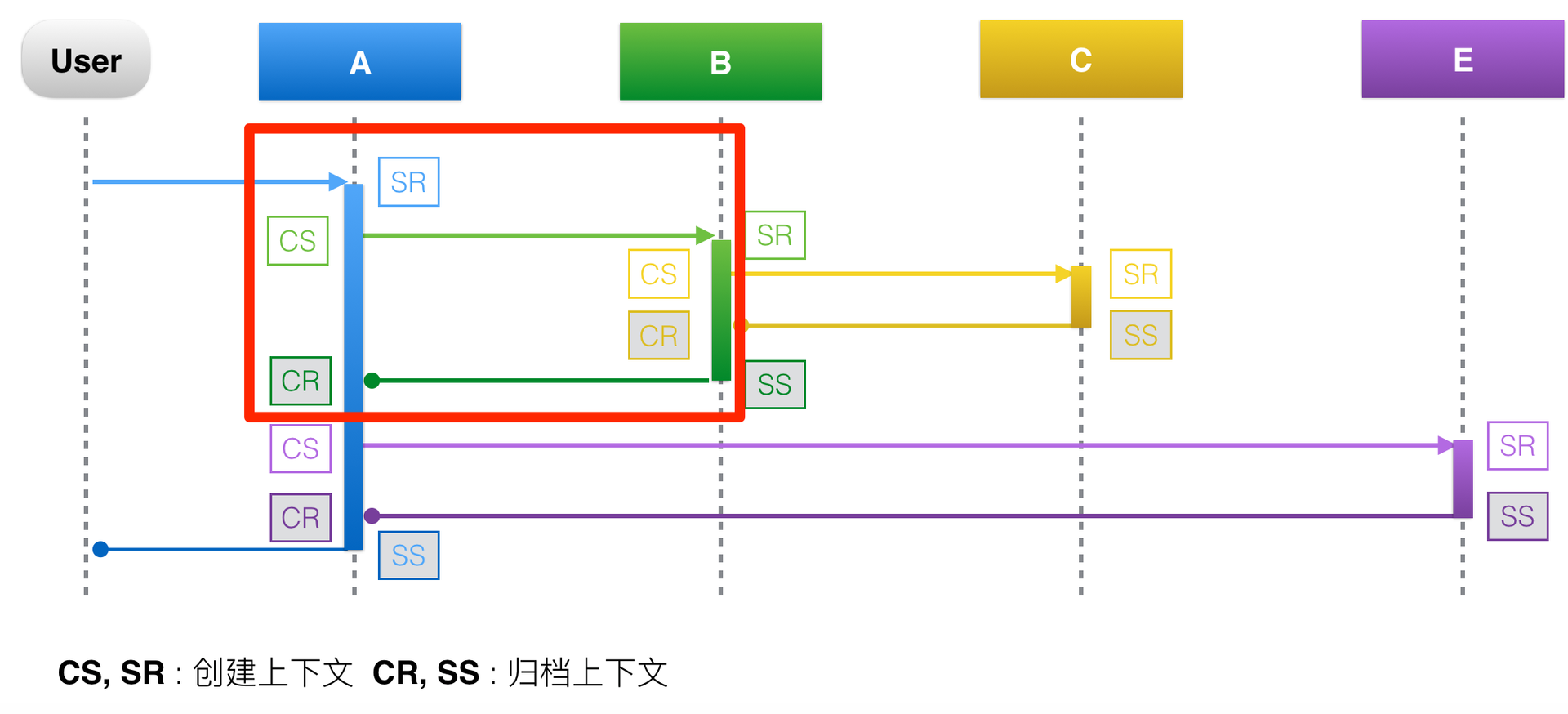
调用链:通过一个全局唯一 ID,将分布在各个节点上的服务的同一次请求串联起来,从而还原调用关系,可以用来追踪系统问题、分析调用数据、统计指标等。
原理
核心概念
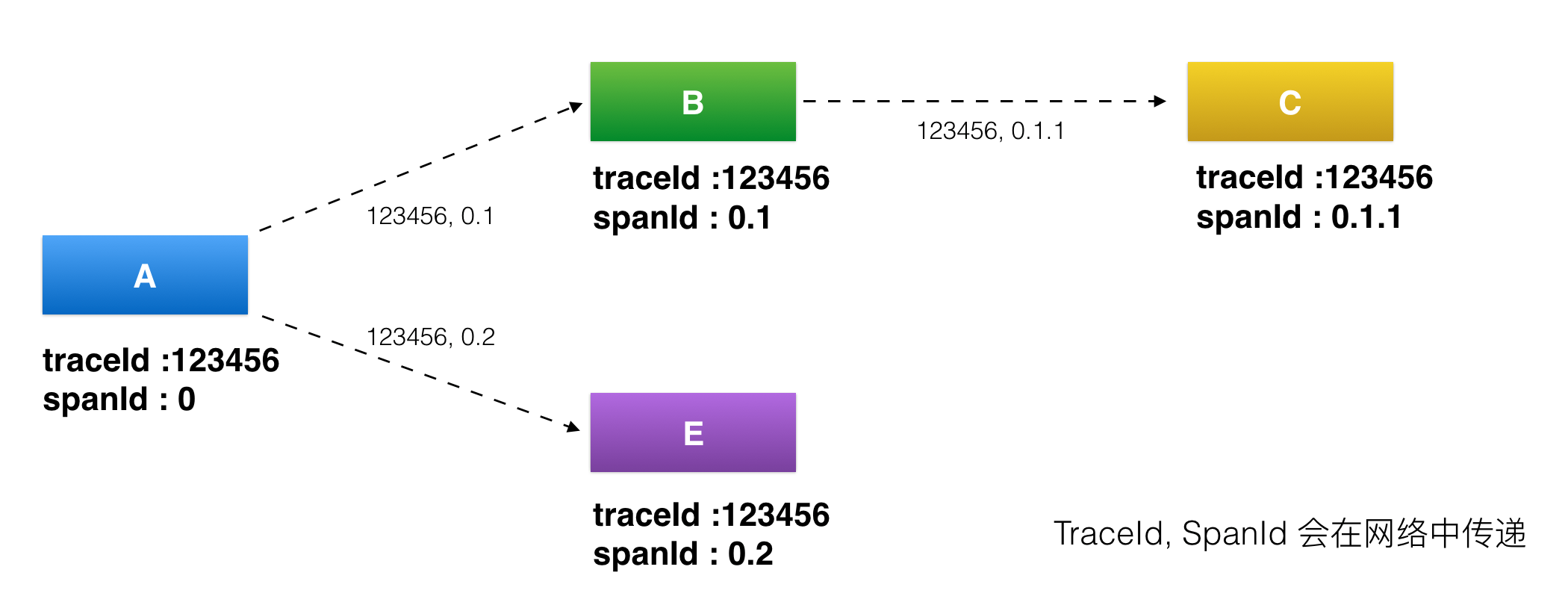
- traceid
- 用于标识某一次请求的具体 ID(在请求调用的第一层生成的全局唯一 ID)
- 随着每次调用不断往后传递(把请求串联起来)
- spanid
- 用于标识一次调用,各服务在分布式请求中的位置(用于定位某一次请求在系统中的位置,以及它的上下游依赖)
- annonation 等
- 用于业务自定义埋点数据
实现
架构分为三层
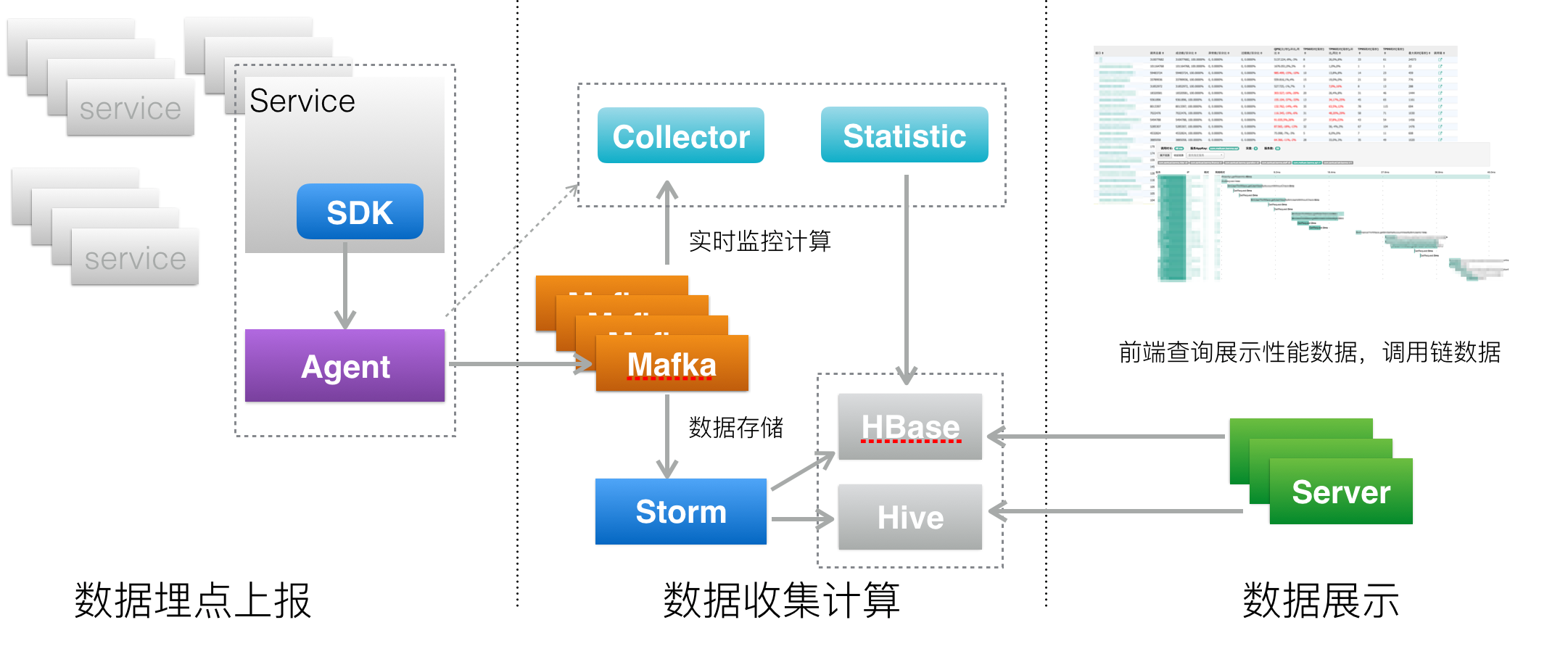
数据采集层
- 作用:负责数据埋点、上报
数据处理层
- 作用:负责数据存储、计算
- 需求分类
- 实时计算(效率要求高)
- 通常使用 Storm、Spark streaming 等聚合
- 通常使用 OLTP 数据仓库存储(HBase 等)
- 离线计算
- 通常使用 MapReduce 聚合
- 通常使用 Hive 存储
- 实时计算(效率要求高)
数据展示层
- 作用:负责数据图形化展示
- 展示方式
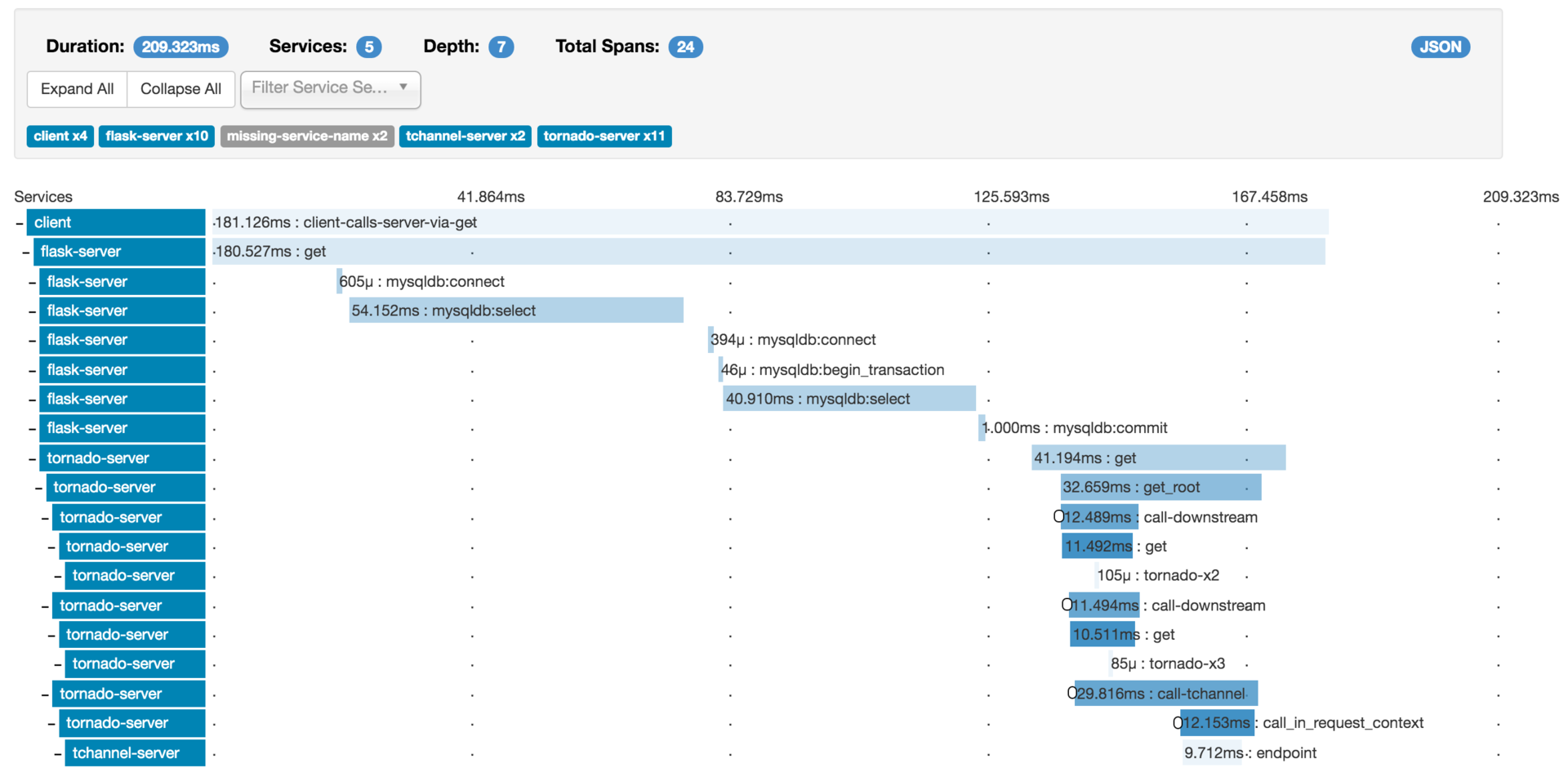
- 调用链路图
- 服务整体情况(调用深度、总耗时等)
- 每一层情况(每层耗时等)

- 调用拓扑图
- 展示系统内包含的服务
- 服务间关系(依赖)
- 依赖调用的 QPS、耗时等
- 调用链路图
落地
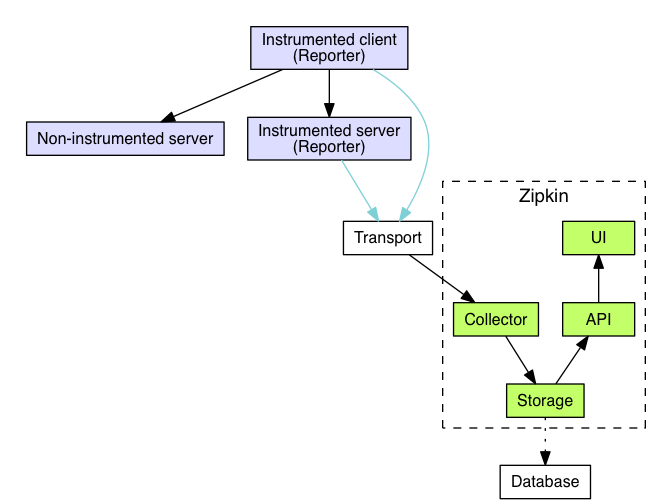
Zipkin
- Collector:负责收集探针 Reporter 埋点采集的数据
- Storage:存储服务调用链路数据(默认使用 Cassandra,也可以使用 ElasticSearch、MySQL)
- API:把链路数据以 API 的形式对外提供
- UI:图形化展示调用链路
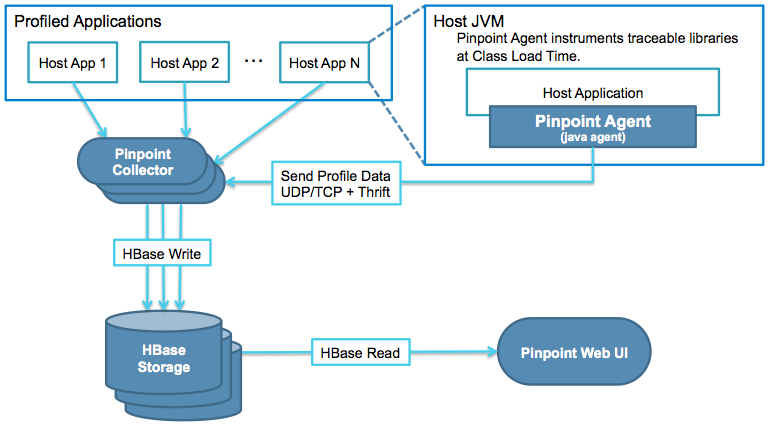
Pinpoint
深度支持 Java。
- Agent:通过 Java 字节码注入方式搜集 JVM中的调用数据,通过 UDP 协议传给 Collector,数据采用 Thrift 协议编码
- Collector:搜集 Agent 传来的数据,存入 HBase
- Storage:采用 HBase 集群方式存储调用链路数据
- UI:通过 Web UI 展示调用链路信息
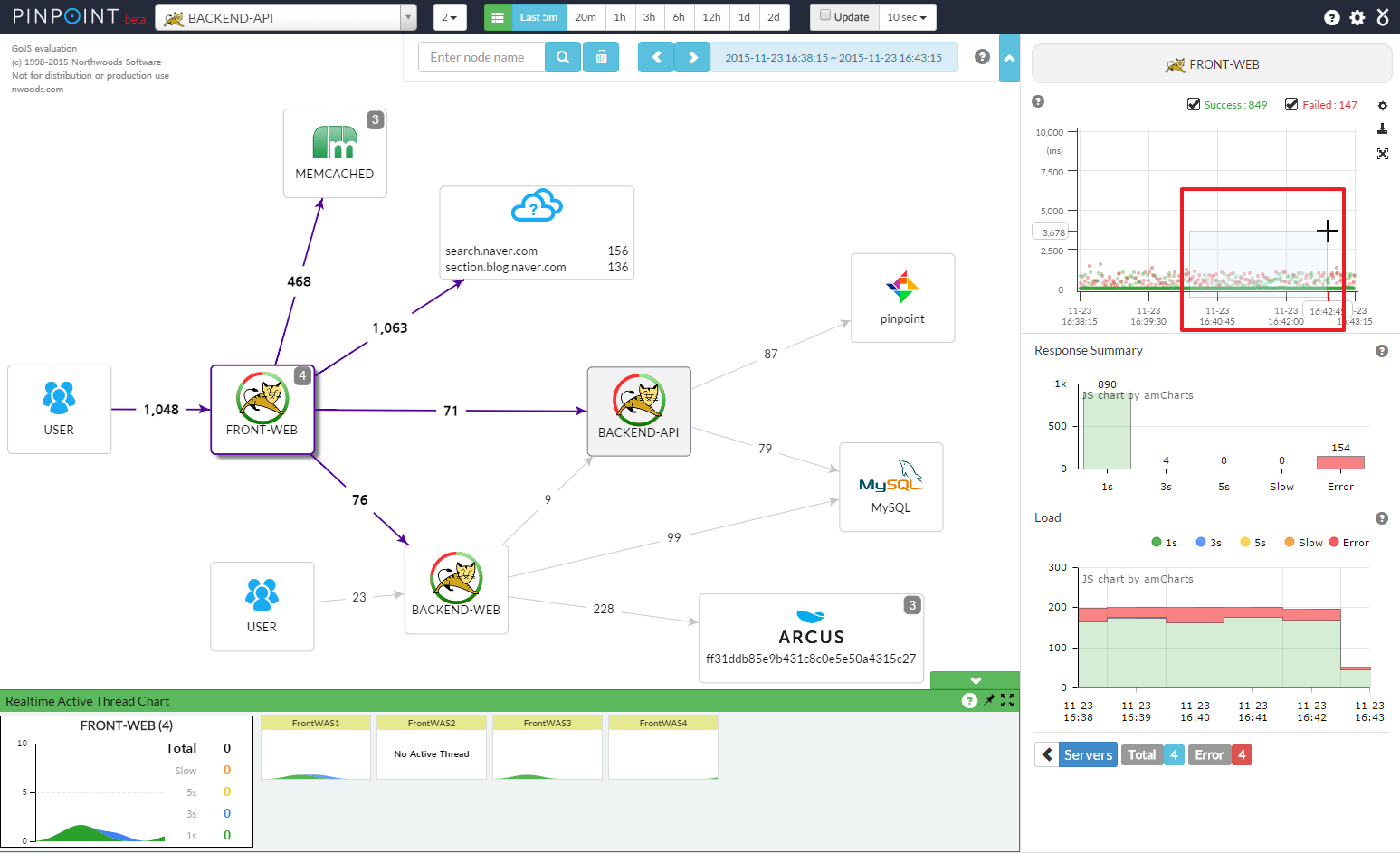
ZIPkin Vs Pinpoint
| 名称 | 支持平台 | 集成难度 | 精确度 | UI 展示 | 备注 |
|---|---|---|---|---|---|
| Zipkin | C#、Go、Java、JavaScript、Ruby、Scala、PHP 等 | 略难(需要引入相关库) | 略低(接口级别) | 只绘制服务间调用链路 | |
| Pinpoint | Java | 简单(字节码注入,无需修改代码) | 高(深入调用链路) | 绘制服务间及 DB 间的调用链路信息 |