内容纲要
多机房部署
大厂(业务量大的厂)出于成本、数据安全等考虑,会自行搭建私有云,组建多机房。
负载均衡
理想环境下通常使用就近原则。
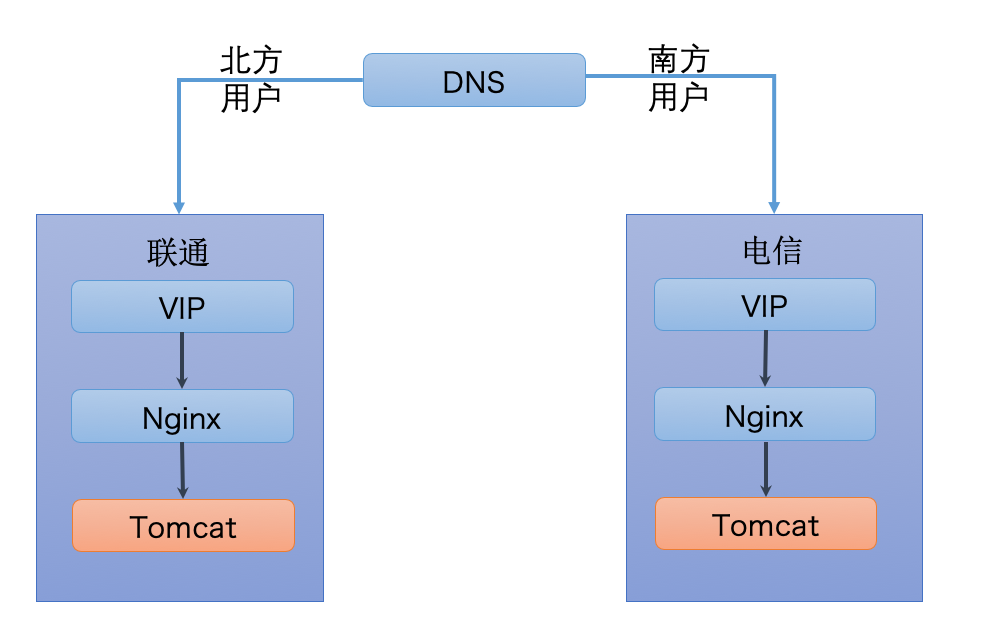
但实际中可能遇到问题:
- 某机房流量大,但不足以支撑线上流量
- 某机房可能出现问题,需要切换流量到其它机房
因此在实际部署中,可能需要根据流量调配,达到各个机房流量均衡的目的。方式有:
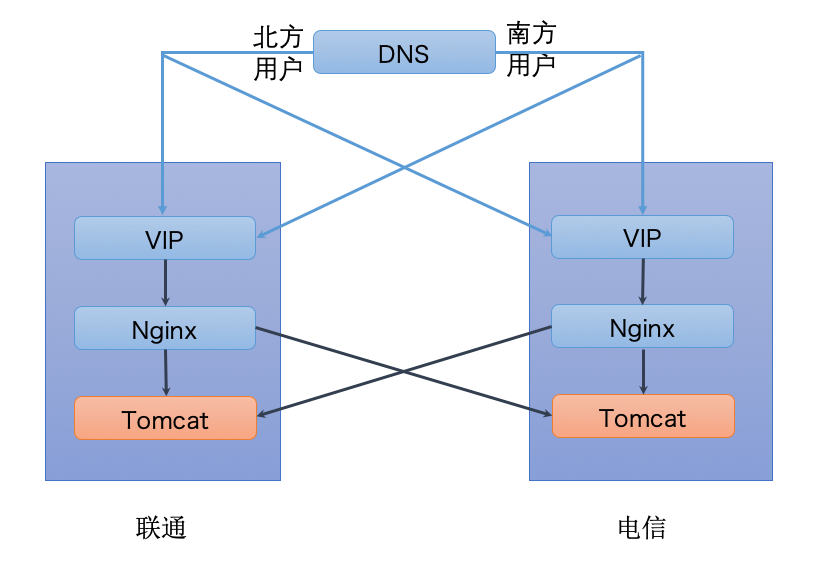
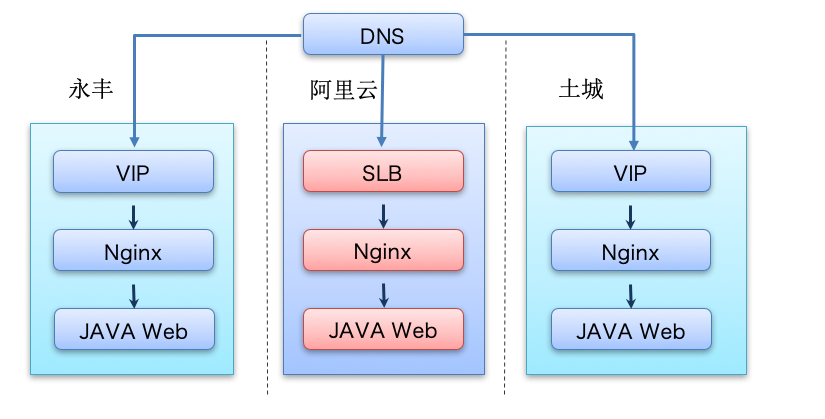
- DNS 解析
- Nginx 转发
数据同步
数据同步除了要考虑数据库数据的同步之外,还需要考虑缓存层的数据一致。同步方案有:
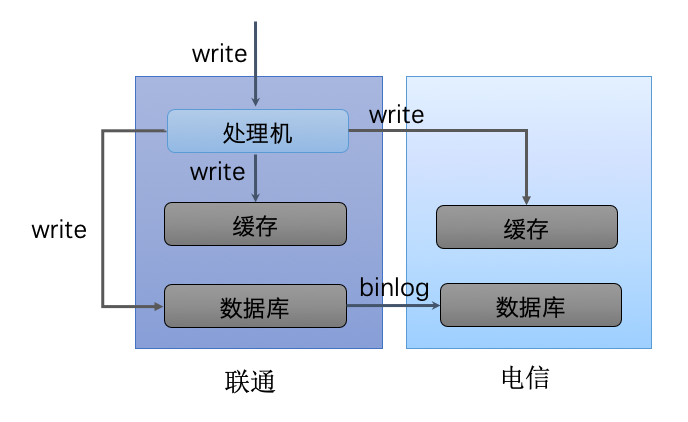
- 主从机房架构
- 原理
- 以一个机房为主机房
- 所有写请求都只发给主机房的处理机
- 主机房处理机更新本机房的缓存和数据库
- 其它机房缓存通过主机房处理机更新缓存
- 数据库通过 binlog 进行同步
- 优点
- 简单
- 缺点
- 风险大:主机房故障影响大
- 原理
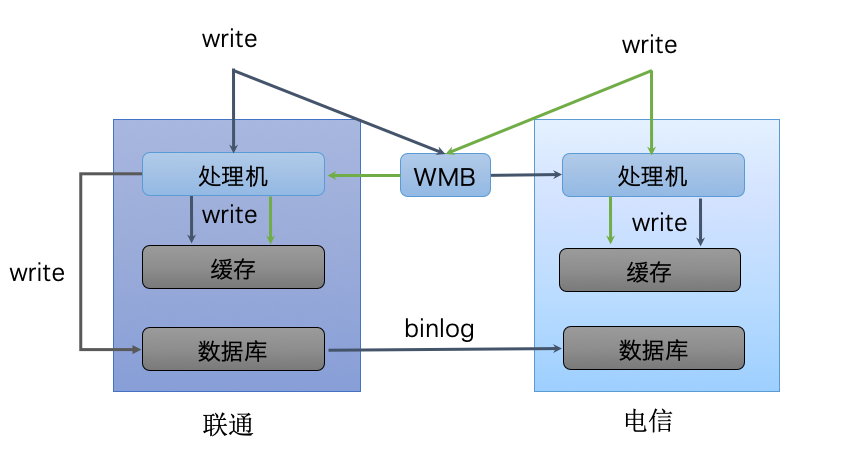
- 独立机房架构
- 原理
- 各机房都接收写请求
- 通过消息同步组件把各自机房的写请求发给其它机房(每个机房都有全量数据)
- 消息组件实现原理
- reship:负责把本机房请求发给其它机房
- collector:负责把读取其它机房的请求,并转发给本机房处理机
- 消息组件实现原理
- 各机房处理机负责更新本机房的缓存
- 其中一个机房更新数据库,其它机房数据库通过 binlog 进行同步
- 优点
- 抗风险能力高(每个机房都有全量数据)
- 缺点
- 实现略复杂
- 流量重复
- 原理
数据一致性
同步过程中可能失败,导致数据不一致。根据不同业务的需求,数据一致性存在多种实现:
- 强一致性(金融类数据)
- 留坑待补
- 最终一致性(社媒类数据)
- 消息对账机制
- 设置一个全局唯一的 requestID
- 在调用中层层传递
- 在处理时不管成功失败,都需要记录处理日志(日志存储到日志系统中)
- 通过定时任务扫描日志,并验证是否成功
- 对失败的请求进行重试,直到成功(达到数据最终一致)
- 消息对账机制
混合云部署
由于业务可能存在高峰、低谷,采购大量的服务器(抗住高峰流量),会加大成本(并且浪费),出于成本考虑,往往会使用混合云(私有云 + 公有云)架构的方式进行部署,来降低成本。
负载均衡
私有云部分依然采用多机房部署的方案,公有云部分通常作为私有云的动态扩展部分,一般不需要特别复杂的设计,使用就近原则进行负载均衡即可。
数据同步
- 私有云与公有云之间的网络隔离
- 通常私有云和公有云之间网络隔离
- 实现互通可以通过架设 VPN 或者专线(跨云双线等)
- 需要保证线路冗余度充足,以免出现其中一条线路故障,流量转移到另一条线路,导致把线路流量打满,导致服务不可用(网络延迟等)
- 数据库上云(考虑数据隐私)
容器运维
- 主机管理
- DCP
- 主机:某一台具体的服务器(可能是私有云的,也可能是公有云的)
- 服务池:针对某个具体服务(由这个服务部署的主机组成,可能是私有云的,也可能是公有云的),规模可能达到几百上千台
- 集群:针对某个业务,可能包含多个服务池
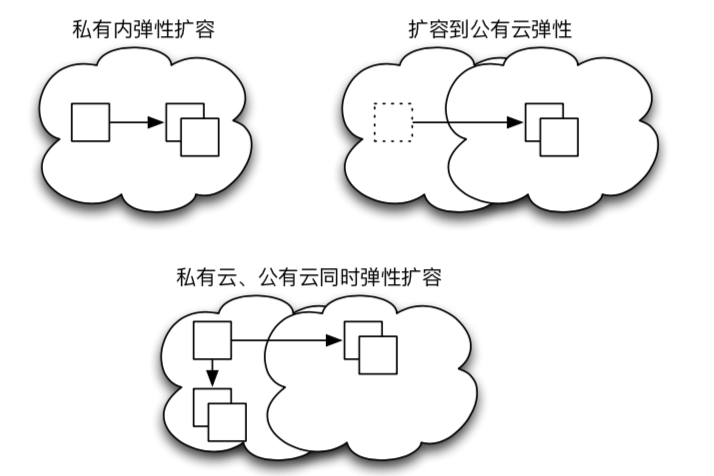
- 扩容
- 私有云弹性扩容
- 公有云弹性扩容
- 私有云、公有云同时弹性扩容
- DCP
- 服务发现
- Nginx
- 负载均衡等
- 弹性扩容
- 原理
- 流量超出私有云容量,扩容公有云,然后切换流量到公有云
- 方式
- DNS 切换(针对大规模流量增长):把原先解析到私有云的 VIP 的流量解析到公有云 SLB
- Nginx 切换
- 原理
- 服务编排
- 关键
- 需要解决跨机房访问问题
- 关键